builds from a
Matrice, keeping at each
position the descriptor number that is selected by a function. A
segment is made for each run of
identical descriptors numbers, and its value is the sum on its
positions of the values returned by the function.
Optional keyword:
func=f
uses function f for selecting the descriptor
number. Function f has two arguments, a Matrice and a position, and
returns a tuple descriptor number, floating point value (default:
returns the tuple best descriptor,best value (the first of the bests
descriptors is returned if there are several bests)).
copy
builds a new Partition by copying this
one;
build_random
builds a
random Partition on a given length with a given number of
segments. Positions of the
segments are uniformly
distributed;
Optional keyword:
ec=ec
sets the minimum length of the segments. It must
be lower than the length of the sequence divided by (the number of
segments +1) (default: 0).
returns a new
Partition by clustering the
Segment given their descriptors
numbers. The argument is a list of numbers lists, each list being a
set of clustered descriptors numbers. In the new Partition,
the resulting Segment have no
descriptors numbers.
Following the increasing positions order, the
Segment are grouped as long as
the set of the descriptors numbers of the group is included in a
list of the argument; if this set is not included in such a list, a
new Segment is built, and the
new set is the descriptors numbers of the considered
Segment;
prediction
computes the
prediction on a
data by a
Lexique, computing one best
descriptor per class, without between
descriptors transitions;
pts_comm
on a
Partition, it returns the number of positions where the
descriptors numbers are the same in both Partition.
outputs in specific format,
without the descriptors patterns.
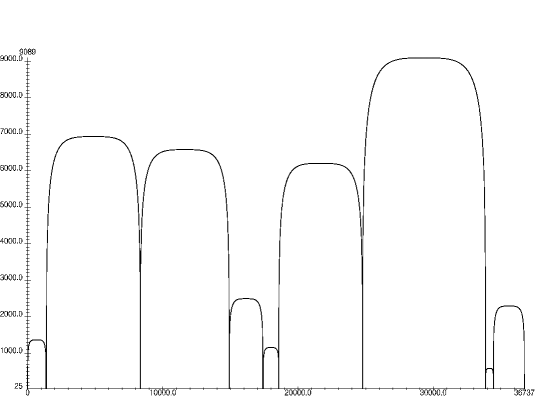
Graphical output
Horizontal axis represents the data, and each segment is drawn by an
arc. The height of each arc is computed by a given function on the
segments (here their lengths).
draw_nf
outputs in postscript language in file of
given name;
Optional keywords:
seg=l
draws only segments which numbers are in list
l;
num=n
if equals 1, numbers of the descriptors are
written;
func=f
the height of each arc is proportional to
value of function f computed on the corresponding
Segment.