R functions for working with syntactic structure coded as token lists (e.g. CONLL format)
You can install from CRAN:
install.packages('rsyntax')Or install the development version from github:
library(devtools)
install_github("vanatteveldt/rsyntax")For a detailed explanation please see this open-access paper. For a quick and dirty demo, keep on reading.
First, we’ll need to parse some data. In the working paper we use the spacyr package (for the spaCy parser), but this requires running Python. Another option that does run in native R is the udpipe package (for the UDPipe parser). The following code automatically downloads the English model and applies it to parse the given text.
library(udpipe)
tokens = udpipe('Mary Jane loves John Smith, and Mary is loved by John', 'english')rsyntax requires the tokens to be in a certain format. The as_tokenindex() function converts a data.frame to this format. For popular parsers in R (spacyr and udpipe) the correct column name specifications are known, so the following is sufficient.
library(rsyntax)
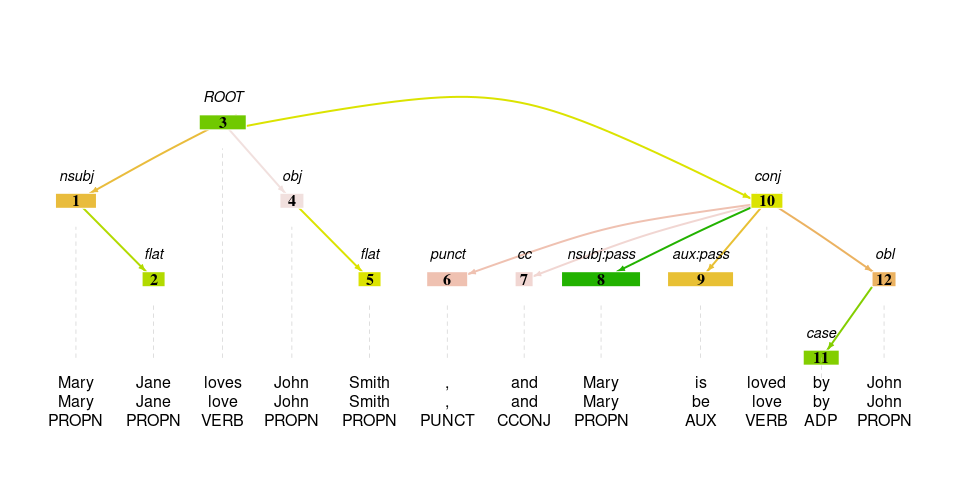
tokens = as_tokenindex(tokens)To query a dependency tree, it is important to have a good understanding of what these trees look like, and how this tree data is represented in a data.frame format. To facilitate this understanding, the plot_tree function visualizes the dependency tree, together with a given selection of columns from the data (see working paper for why this is possible for most types of dependency trees).
plot_tree(tokens, token, lemma, upos)
Note that this function only prints one sentence a time, so if the sentence is not specified it uses the first sentence in the data.
The main functionality of rsyntax is that you can query the
dependency tree. While there are several query languages for networks,
these are quite complicated and not specialized for querying dependency
trees. We therefore developed a new query format that is (supposed to
be) easy to understand if you undestand R data.frames. The first step is
to create the query using the tquery function.
Firstly, you can provide lookup values for selecting rows from the data.frame. For example, the following query would find all rows where the upos value is either “VERB” or “PROPN”:
tquery(upos = c("VERB", "PROPN"))To query the edges of a dependency tree, you can perform another row lookup for the parents or children of the results of this query, by nesting the parents() and children() functions. The following query says: for all tokens (i.e. rows) where upos has the value “VERB”, find the ones that have a child for which the relation column has the value “nsubj”.
tq = tquery(upos = 'VERB',
children(relation = 'nsubj'))You can look up multiple parents and children, and also nest parents and children within each other to query larger parts of the tree.
The above query only finds a match. To see which tokens are matched you need to provide labels for the parts of the query that you want to find. The following query looks for a simple direct clause with a verb, subject and object.
direct = tquery(label = 'verb', upos = 'VERB',
children(label = 'subject', relation = 'nsubj'),
children(label = 'object', relation = 'obj'))Specifically this says: find all tokens where upos is “VERB”, and that have a child with the relation “nsubj” AND a child with the relation “obj”. If this condition is met, give these tokens the labels “verb”, “subject” and “object”.
With the annotate function, we can use this tquery to add these labels to the token data. Here we say that we use the column name “clause” for these labels.
tokens = annotate_tqueries(tokens, 'clause', direct)
tokens[,c('doc_id','sentence','token','clause','clause_fill')]
#> doc_id sentence token clause clause_fill
#> 1: doc1 1 Mary subject 0
#> 2: doc1 1 Jane subject 1
#> 3: doc1 1 loves verb 0
#> 4: doc1 1 John object 0
#> 5: doc1 1 Smith object 1
#> 6: doc1 1 , verb 2
#> 7: doc1 1 and verb 2
#> 8: doc1 1 Mary verb 2
#> 9: doc1 1 is verb 2
#> 10: doc1 1 loved verb 1
#> 11: doc1 1 by verb 3
#> 12: doc1 1 John verb 2In the output we see that “Mary Jane” is labeled as subject, “loves” is labeled as verb, but also that ALL the rest is labeled as object, including “, and Mary is loved by John”. The reason for this is that by default, rsyntax will label all children of a matched token with the same label. We call this behavior the “fill” heuristic. In the clause_fill column you also see at what level a token was matched. The value 0 means the match itself, 1 means a direct child, etc. The default setting to fill all children is weird in this example, but in the next section we show how this behavior can be customized.
In our example sentence, we could turn off fill (with the
fill = F argument) so only John is matched as the object,
but a better solution would be to control what specific nodes to fill by
nesting the fill() function. For example, we can say that
for the subject and object we only want to ‘fill’ the tokens that form a
multiword expression (MWE). In Universal Dependencies this is indicated
with the ‘flat’, ‘fixed’ and ‘compound’ relations (see the (Universal
Dependencies Relations table)[https://universaldependencies.org/u/dep/]). Here we use
the fill function to specify that we only want to fill tokens where the
relation has one of these values. Note that specifying lookup values in
fill() works in the same way as in the
children() function.
fill_mwe = fill(relation = c('flat','fixed','compount'),
connected=T)Next to giving the lookup values for the relation column, we specify
that connected = TRUE. This determines how lookup values
are applied for longer branches of children (children ->
grandchildren -> etc.). If connected is TRUE, then whenever a token
does not satisfy the lookup values, the tquery will stop looking in this
branch. So, in our current example, if the direct child is not a MWE,
the grandchild will not be filled even if it is a MWE. For multiword
expressions this makes sense, because if tokens with ‘flat’, ‘fixed’ or
‘compound’ relations are not directly connected, they are part of
different multiword expressions.
For reference, if connected is FALSE (which is the default), fill will get all the children, grandchildren, etc., and then filter them based on the lookup values.
To use the fill() function in a tquery, we simply pass
it to one (or multiple) of the labeled nodes, similar to how you would
pass the children function. Here we use the
fill_mwe as specified above for both the subject and object
nodes. Also, we set fill = F for the ‘verb’ node, as an
example of how to disable fill for a specific node.
direct = tquery(label = 'verb', upos = 'VERB', fill=F,
children(label = 'subject', relation = 'nsubj',
fill_mwe),
children(label = 'object', relation = 'obj',
fill_mwe))Note that it would also have been possible to directly type this
fill() function within the tquery, instead of first assigning it to
fill_mwe. This is a matter of preference, but if you have
specific fill settings that you want to use multiple times, the above
approach is a good strategy to reduce redundancy in your code.
In case you didn’t believe us, this actually works. Here we run the
annotate_tqueries function again. Very importantly, note that we add the
overwrite = TRUE argument, which means that we’ll overwrite
the previous “clause” column. (By default, annotate would not overwrite
previous results, which enables another way of chaining queries that we
won’t discuss here.)
tokens = annotate_tqueries(tokens, 'clause', direct, overwrite = T)
tokens[,c('doc_id','sentence','token','clause','clause_fill')]
#> doc_id sentence token clause clause_fill
#> 1: doc1 1 Mary subject 0
#> 2: doc1 1 Jane subject 1
#> 3: doc1 1 loves verb 0
#> 4: doc1 1 John object 0
#> 5: doc1 1 Smith object 1
#> 6: doc1 1 , <NA> NA
#> 7: doc1 1 and <NA> NA
#> 8: doc1 1 Mary <NA> NA
#> 9: doc1 1 is <NA> NA
#> 10: doc1 1 loved <NA> NA
#> 11: doc1 1 by <NA> NA
#> 12: doc1 1 John <NA> NAOur direct tquery does not capture “Mary is loved by
John”, in which the relation is expressed in a passive form. More
generally speaking, there are different ways in which people express
certain semantic relations in language, so to capture all (or at least
most) of them you will have to combine multiple tqueries. How many
queries you’ll need depends on what you want to do, but in our
experience only a few queries are needed to get good performance on
tasks such as quote and clause extraction.
For our current example, we only need to add an additional query for
subject-verb-object relations in a passive sentence. Here we again only
use a simple version where the subject and obj are explicitly specified.
Note that we also re-use fill_mwe as specified above.
passive = tquery(label = 'verb', upos = 'VERB', fill=FALSE,
children(label = 'subject', relation = 'obl', fill_mwe),
children(label = 'object', relation = 'nsubj:pass', fill_mwe))Now we can add both tqueries to the annotate function. For convenience, we can also specify labels for the queries by passing them as named arguments. Here we label the direct query “dir” and the passive query “pas”. Also, note that we again use overwrite = TRUE.
tokens = annotate_tqueries(tokens, 'clause',
dir = direct,
pas = passive,
overwrite = TRUE)
tokens[,c('doc_id','sentence','token','clause', 'clause_id')]
#> doc_id sentence token clause clause_id
#> 1: doc1 1 Mary subject dir#doc1.1.3
#> 2: doc1 1 Jane subject dir#doc1.1.3
#> 3: doc1 1 loves verb dir#doc1.1.3
#> 4: doc1 1 John object dir#doc1.1.3
#> 5: doc1 1 Smith object dir#doc1.1.3
#> 6: doc1 1 , <NA> <NA>
#> 7: doc1 1 and <NA> <NA>
#> 8: doc1 1 Mary object pas#doc1.1.10
#> 9: doc1 1 is <NA> <NA>
#> 10: doc1 1 loved verb pas#doc1.1.10
#> 11: doc1 1 by <NA> <NA>
#> 12: doc1 1 John subject pas#doc1.1.10This time, the sentence has two annotations. In the clause_id column you can also see that the first one was found with the direct (dir) tquery, and the second one with the passive (pas) tquery.
This can also be visualized with the plot_tree
function.
plot_tree(tokens, token, lemma, upos, annotation='clause')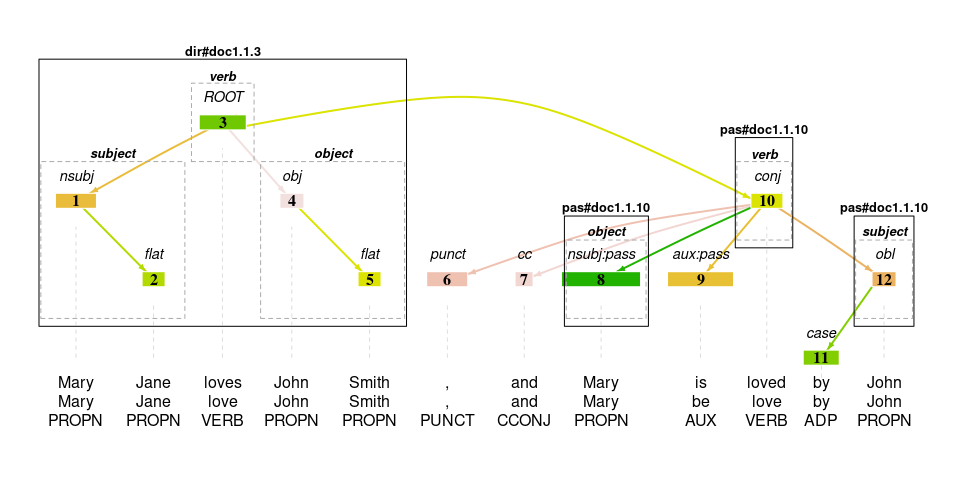
In the current example, there are no nodes that match both queries, but this will often be the case. One of the most important features of rsyntax (compared to using more general purpose graph querying languages) is that the ‘chaining’ of queries is specialised for the task of annotating tokens.
When multiple tqueries are passed to annotate_tqueries,
each token can only be matched once. In case multiple queries match the
same token, the following rules are applied to determine which query
wins.
This has two important advantages. Firstly, allowing tokens to have only one annotation keeps the data.frame nice and tidy, for a happy Hadley. Secondly, this enables an easy workflow for improving the precision and recall of your annotations.
The general idea is to put specific queries (high precision, low recall) at the front of the chain, and broad queries (high recall, low precision) at the end. If your recall is low, you can add broad queries to the end of the chain. If there are cases whether a query incorrectly matches a pattern, you can add queries for this specific pattern to the front to increase the precision.
If the quick and dirty tutorial piqued you interest, we recommend reading the working paper for more advanced features and some background on what we ourselves use this package for. For instance, the rsyntax package also supports more advanced features for writing and piping queries. Furthermore, since language can get quite complicated (gotta love concatenations, relative clauses and recursion), rsyntax also provides functions for transforming and cutting up dependency trees. How to best use this is still something we’re experimenting with.
Aside from the rsyntax package we will (soon?) create a github repository for an rsyntax cookbook, to share the queries and transformation that we use in our own research. If you are interested in using rsyntax and have any questions, concerns or ideas, please do contact us.