Machine learning is widely used in information-systems design. Yet, training algorithms on imbalanced datasets may severely affect performance on unseen data. For example, in some cases in healthcare, fintech, or cybersecurity contexts, certain subclasses are difficult to learn because they are underrepresented in training data. This R package offers a flexible and efficient solution based on a new synthetic average neighborhood sampling algorithm (SANSA), which, in contrast to other solutions, introduces a novel “placement” parameter that can be tuned to adapt to each dataset’s unique manifestation of the imbalance.
You can install the released version of sansa from CRAN with:
install.packages("sansa")And the development version from GitHub with:
# install.packages("devtools")
devtools::install_github("murtaza-nasir/sansa")Lets first load some libraries.
library(sansa)
library(ggplot2)Now lets generate an imbalanced dataset.
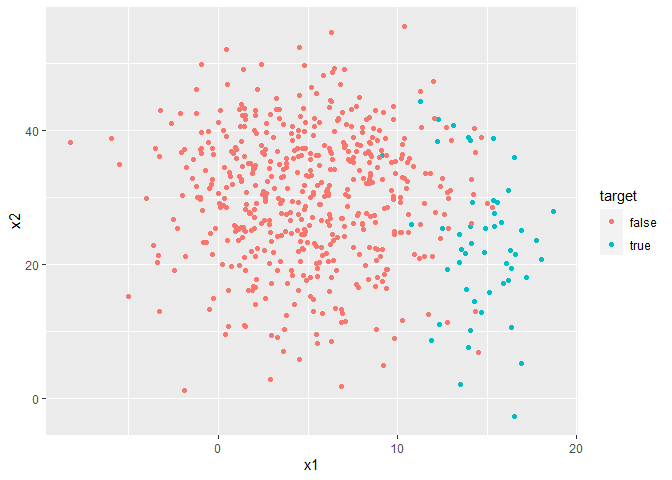
minority = data.frame(x1 = rnorm(50, 15, 2),
x2 = rnorm(50, 25, 10),
target = "true")
majority = data.frame(x1 = rnorm(500, 5, 4),
x2 = rnorm(500, 30, 10),
target = "false")
dataset = rbind(minority, majority)
ggplot(dataset) + geom_point(aes(x1, x2, color = target))
This imbalanced dataset can be balanced by SANSA using the
sansa function.
sansaobject = sansa(x = dataset[,1:2], y = dataset$target, lambda = 1, ksel = 3)
balanced <- sansaobject$x
balanced$target = sansaobject$y
ggplot(balanced) + geom_point(aes(x1, x2, color = target))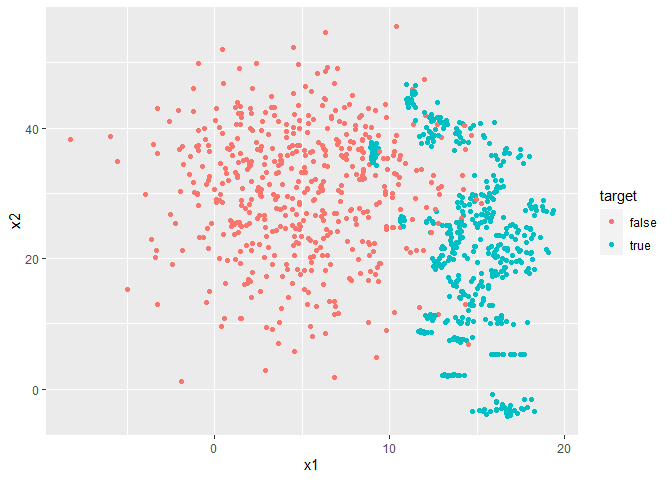
SANSA returns a list object that can be used directly within the
caret training pipeline.
Details about the algorithm as well as benchmarks are available in the accompanying publication that will be added here shortly.