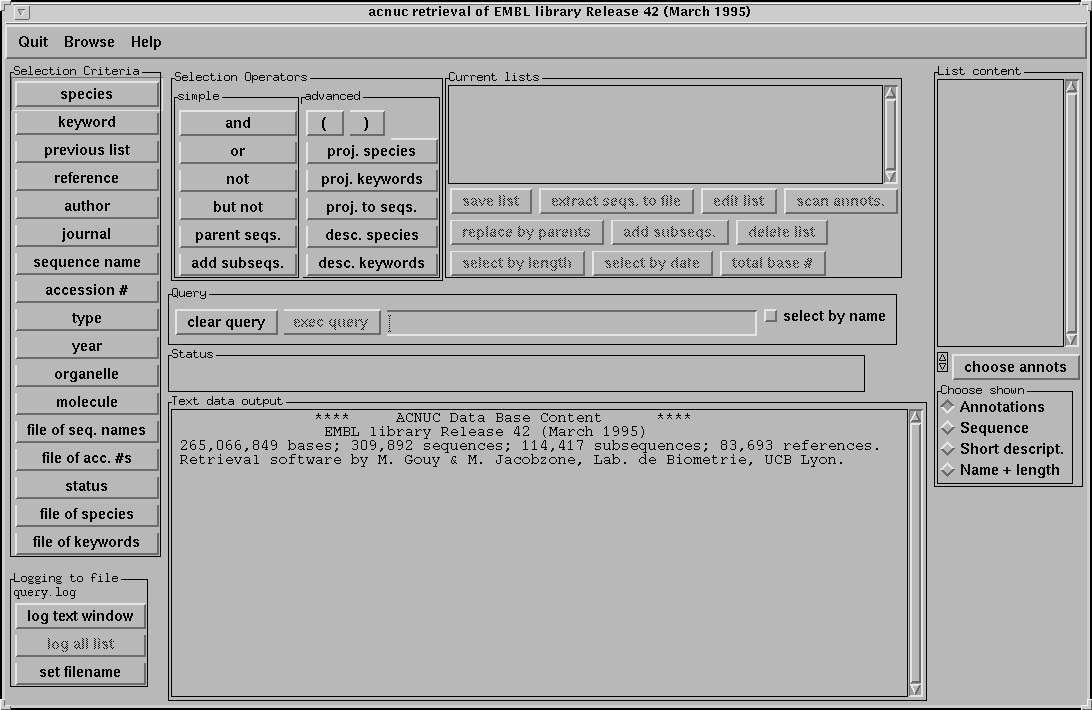
This program deals with sequence lists that group all sequences matching the retrieval criteria employed. Lists are named by the program list1, list2... Many lists can be handled simultaneously, and old lists can be used to derive new ones. Lists of species and of keywords can also be used for more elaborate usage.
Notion of PARENT SEQUENCES / SUBSEQUENCES (for nucleic acid sequence databases only):
Each database entry appears in ACNUC as a parent sequence.
In addition, each coding region (i.e., CDS, rRNA, tRNA, scRNA, misc_RNA) listed in the features table of a sequence gives rise to a subsequence spliced from one or several parent sequences.
Thus direct, automatic access to coding regions excluding introns and flanking
regions, is possible.
Subsequences are named by adding an extension (e.g., .PE1, .RR2) to the name of the parent sequence whose features table defines the subsequence.
Subsequences are selected when a type selection criterion is used, possibly in combination with other criteria.
This program has a graphical user interface.
Content of menu bar
- Quit : exit of the program
- Browse: allow to browse through all species or keywords
- General help
- Help mode :
- When this mode is activated, clicking on any button or panel gives help about its function.
- Deactivate Help mode of menu Help to return to normal program use.

{kind=link}