Homologous Sequences in Complete Genomes Database
HOGENOM release 01 Updated on 8th September 2003
|
Release informations:
Protein
Nucleotide
Query Hogenom
Hogenom
HOGENOM is a database of homologous genes from fully sequenced organisms, structured under
ACNUC sequence database management system.
It allows one to select sets of homologous genes among species,
and to visualize multiple alignments and phylogenetic trees. Thus HOGENOM
is particularly useful for comparative sequence analysis, phylogeny and
molecular evolution studies. More generaly, HOGENOM gives an overall view
of what is known about a peculiar gene family.
Content
The database itself contains all protein sequences from the EBI
proteomes data,
with some data corrected, clarified or completed
(notably to address the problem of redundancy and
orthology/paralogy)and with some annotation modifications.
It contains also all the corresponding nucleotide sequences in EMBL.
Homologous proteins are classified into families and multiple alignments and phylogenetic trees
are computed for each family.
Sequences and related information have been structured in an ACNUC database.
The description on how the database is built is available
here.
The present version of HOGENOM is release 01 (September 2003). It has been built
using sequences from the European Bioinformatics Institute
proteome data (18 June 2003). It
contains a total of 423,577 sequences protein sequences
(and 527,928 nucleic sequences) classified in
157,279 families.
Among all the proteins included in this release, 305,514 (72%) are classified
into 41,907 families containing at least two sequences, 115,373 (27%) are unique
in their family and 2,690 (1%) partial proteins are not attached to a family.
The size distribution of the HOGENOM families is described here.
Fully Sequenced Organisms
The list of the organisms in HOGENOM is given here.
There is 117 organims, among which 10 are eukarya
(Guillardia theta, Mus musculus, Rattus norvegicus, Arabidopsis thaliana,
Caenorhabditis elegans, Drosophila melanogaster,Encephalitozoon cuniculi,
Saccharomyces cerevisiae, Homo sapiens, Schizosaccharomyces pombe)
and 16 are archaea.
Among all the proteins, 31% belong to eukarya, 60% belong to bacteria and 9% belong to archaea.
Graphical User Interface
HOGENOM interface is based on a client/server architecture. To access
the database you only need to install the FamFetch
application on your computer. This program, written in Java, integrates a GUI that allows
users to easily access and visualize:
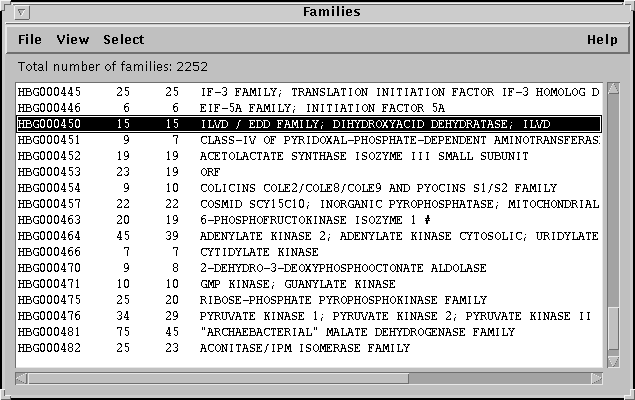
- The list of the families available in the database.
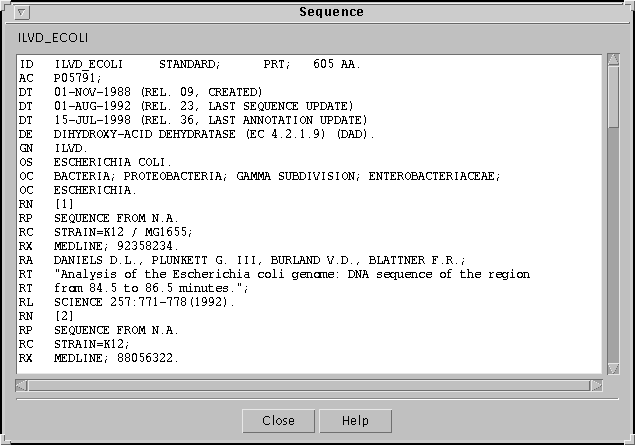
- The sequence (protein or nucleotide) of the genes
defining these families.
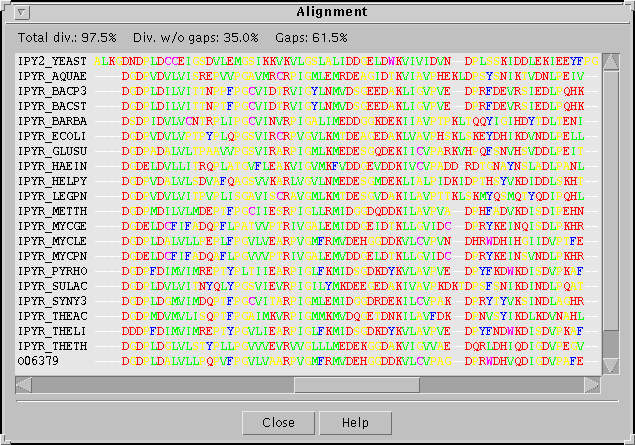
- The alignments built with these families.
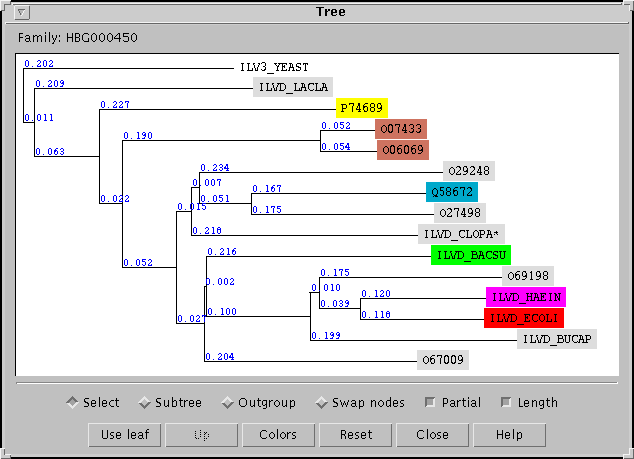
- The phylogenetic trees computed with these alignments.
In FamFetch phylogenetic trees, genes are colored according to the species
from which they come.
The user can modify the color table according to the taxa (any taxonomic level) he is interested in.
This color table is saved in a file of preferences (named .hobacfetch in UNIX, HobacFetch.Prefs in MaOS, HobacFetch.ini in Windows systems).
The color table that is installed by default with FamFetch is dedicated to prokaryotes (for the HOBACGEN database).
You can replace this preference file by the one we have prepared for HOGENOM, that is available here.
WWW access
It is also possible to query the database on this server through the
WWW-Query and Cross-Taxa systems. Note that
HOGENOM is splitted into two databases on this server: HOGENPROT
contains the protein sequences from EBI proteome data while HOGENNUCL
contains the nucleotide sequences from EMBL.
Server mirroring
You don't need to install the server itself to have HOGENOM running on your
computer as the client is enough for that purpose. On the other hand
you may want to set-up your own server in a way to speed up your
database access and to propose that service to potential users in your
geographic area. To install an HOGENOM server, you need first to
register. Starting from the
registering page results, you will have access to the server installation
procedure.
The whole database is available from our FTP server at URL:
ftp://pbil.univ-lyon1.fr/pub/hogenom/
Note that it is much more efficient to use a dedicated FTP client to download the
database rather than an Internet Web browser.
Important note: the SWISS-PROT entries such as those found in HOGENOM are
copyrighted. They are produced through a collaboration between the Swiss Institute
of Bioinformatics and the European Bioinformatics Institute. There are no restrictions
on its use by non-profit institutions as long as its content is in no way modified.
Usage by and for commercial entities requires a
license agreement
(See or send an Email to license@isb-sib.ch).
Contact and reference
If you encounter some problems when installing or using HOGENOM, please
contact Laurent Duret.
Also we welcome any comments or suggestions on the database and/or its
interface.
Acknowledgements
This project is supported
If you have problems or comments...
 Back to PBIL home page
Back to PBIL home page
{kind=link}
{kind=link}
{kind=link}
{kind=link}